
나의 기록
[Python] 데이터 집계 , Group by, Pivot table 본문
1. GROUP BY



- 카테고리 그룹별로 연산


df.groupby('Category').mean()
df.groupby('Category').sum()
df.groupby('Category').count()
df.groupby('Category').max()
df.groupby('Category').min()

tips_data.csv 활용해서 연습
df[['sex','day','total_bill', 'tip', 'size']].groupby(['sex', 'day']).mean()

group by를 sex랑 day 기준으로 해준 것임.
df[['sex','day','total_bill', 'tip', 'size']].groupby(['sex', 'day']).agg({'total_bill': 'max', 'tip':'mean', 'size': 'sum'})

복수의 열을 기준으로 그룹화하여 데이터프레임을 조작하는 경우, groupby() 함수에 복수의 열을 리스트로 전달하여 원하는 그룹화 기준을 지정하고, agg() 함수를 사용하여 여러 열에 대해 다양한 집계 함수를 적용할 수 있습니다.
2. Pivot Table
df = pd.DataFrame({
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [10, 20, 30, 40, 50]
})
df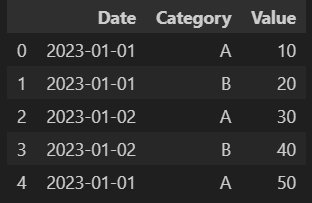
pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum')
pivot
df = pd.DataFrame({
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01'],
'Category': ['A', 'B', 'A', 'B', 'A'],
'SubCategory': ['X', 'Y', 'X', 'Y', 'X'],
'Value': [10, 20, 30, 40, 50]
})
dfsubcategory 추가

pivot = df.pivot_table(index='Date', columns=['Category', 'SubCategory'], values='Value', aggfunc='sum')
pivot
☑️ 데이터 정렬하기
1. sort_values() 함수:
- 컬럼 기준으로 정렬

sorted_by_score = df.sort_values('Score') # 'Score' 열을 기준으로 오름차순 정렬
sorted_by_score = df.sort_values('Score',ascending=False) # 'Score' 열을 기준으로 내림차순 정렬

=> Age와 Score 기준으로 각각 나눠주고 , 각각 오름차순, 내림차순
sort_index() 함수: 인덱스를 기준으로 정렬
df.sort_index() # 인덱스를 기준으로 오름차순 정렬
df.sort_index(ascending=False) # 인덱스를 기준으로 내림차순 정렬
'개발일지 > Python' 카테고리의 다른 글
| [Python] 데이터 분석 기초 과제 (1) | 2024.01.26 |
|---|---|
| [Python] 데이터 시각화 (2) | 2024.01.25 |
| [Python] 데이터 병합, concat()함수, merge()함수 (0) | 2024.01.25 |
| [Python] 데이터전처리(2) Boolean Indexing, (1) | 2024.01.25 |
| [Python] 1.데이터 전처리 (데이터저장,불러오기,컬럼,인덱스,데이터확인,.loc,.iloc) (0) | 2024.01.24 |
'개발일지/Python' Related Articles
more



