
나의 기록
[TIL / Today I Learned] 20231228 프로덕트 개선은 정말 도움이 되었을까?_ 전처리 및 분석 및 시각화 본문
[TIL / Today I Learned] 20231228 프로덕트 개선은 정말 도움이 되었을까?_ 전처리 및 분석 및 시각화
리베린 2023. 12. 28. 20:29[데이터분석] 프로덕트 개선은 정말 도움이 되었을까?_ 전처리 및 분석
(1) 데이터, 라이브러리 불러오기 및 데이터 읽어보기
- Pandas, numpy, matplotlib 사용 선언하기 및 분석할 데이터 불러 오기
|
#라이브러리 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_table('/content/cohort_data.csv',sep=',')
|
(2) 표 읽기 및 필요한 데이터 살펴 보기
|
#테이블 하위 5개의 정보 확인하기
sparta_data.tail()
|

⇒ user_id: 수강생 고유 id
⇒ created_at: 수강 등록 시점
⇒ name: 수강생 이름
⇒ progress_rate: 진도율
📌 우리는 “수강 완료” 하는데, 얼마만큼 “걸린 시간”을 알아야 합니다!
created_at: 수강 등록 시점
progress_rate: 진도율
(3) 데이터 전처리 하기
=> 고객의 수강 시점을 “일(day)”에서 “주 단위(week)”로, 그리고 각 수강생의 “진도율”을 “강의 주차”로 변경
- 이 과정을 거치는 이유:
⇒ 일(day)로 데이터를 분석 한다면, TMI 너무 많은 정보로, 결과를 한 눈에 파악하기 힘듦
⇒ 우리는 '진도율'이 아니라 주차 별로 “수강 전환율”을 알고 싶기에, 그 진도에 해당하는 “주차”의 정보도 필요
step1) 각 고객별 최소 수강 주 (week) 구하기 :
“년, 월, 일”로 이루어 진 것을 1년 중 “몇주차” 에 있는지 나타내기
(1) created_at 데이터 종류를 확인 해봅시다! : 날짜 데이터 타입 확인 하기
|
#파이썬의 created_at함수를 쓰면, 데이터의 종류를 확인 할수 있어요 :) print(type(sparta_data['created_at'][1]))
#sparta_date 정보에서 created_at 열에서 데이터 첫번째 부분만 확인 하면 되겠죠?
|
=> created_at 는 날짜 및 시간이 아닌 “문자열”로 저장되어 있음.
=> 시간의 형태로 바꾸어야 함.
(2) 우리가 원하는 시간의 데이터 형태로 변경하기
- 날짜 원하는 형태로 지정하기
- %Y는 년도
- %m은 월
- %d는 일
- 날짜 데이터로 변경하기
|
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['start_time'] = pd.to_datetime(sparta_data['created_at'], format=format, infer_datetime_format=True)
sparta_data.tail()
|
- 여기서 잠깐 ✋🏻 to_datetime() 은 무엇일까요? 🤔
- 괄호 안, 해당 열의 데이터를 날짜와 시간 데이터로 변경 해주는 함수예요 :)
- ⇒ infer_datetime_format=True : datetime이 어떤 형식으로 이루어졌는지 확인 후 자동으로 변환 해주는 설정을 한 것입니다!
=> 새로운 날짜 컬럼이 생성 되었음.
(3) 수강 시작 주(week) 열 추가하기
|
#수강 시작 주 구하고, 테이블의 열로 추가 하기
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
sparta_data.tail()
|
- 여기서 잠깐 ✋🏻 .dt.isocalendar().week은 무엇인가요?
- ⇒ .dt.isocalendar().week ⇒ 날짜를 주(week) 로 변경 할수 있습니다.
- week 대신, year 혹은 day으로 해당 날짜의 년도, 일자도 가져 올 수 있습니다.
- 처음 수강 시작한 주 범위 확인 하기
|
#이전에 배웠듯이 set()은 set안의 데이터는 순서가 정해져있지 않고, 중복되지 않는 고유한 요소를 가져옵니다!
category_range = set(sparta_data['start_week'])
category_range
|

step 2) 진도율을 강의 주차로 변경 하기 : 현재 우리게 주어진 건 수강율입니다! 하지만, 특정 수강생이 “어느 주차”에 있는지 아는것이 중요하죠! 수강율을 수강 주차로 변경 시켜 봅시다!
(1) 진도율을 강의 주차로 변경 하기
|
0주차 : 0 ~4 .11%
1주차 : 4.12% ~ 26.03%
2주차 : 26.04% ~ 41.10%
3주차 : 41.11% ~ 61.64%
4주차 : 61.65% ~ 80.82%
5주차 : 80.83% ~ 100%
|
(2) 범주화 할 데이터 리스트로 만들기
|
progress_rate = list(sparta_data['progress_rate'])
|

… 이렇게 “수강율” 모아둔 긴 리스트가 출력
(3) 범주를 구분하는 기준 및 라벨(수강 주차) 만들기
|
#범주를 구분하는 기준 bins 처음(0)과 끝(100) 잊지 말고 기입 해주세요!
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
#구분한 범주의 라벨 labels
labels=[0,1,2,3,4,5]
|
(4) 진도율에 따라 주차별로 변경하기
|
#범주화에 사용하는 함수 pd.cut
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labels)
cuts
|

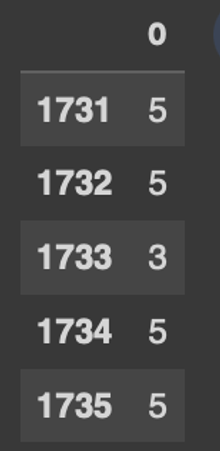
범주화 결과물을 테이블로 변경하기
|
#결과물을 테이블로 변경하기
cuts = pd.DataFrame(cuts)
cuts.tail()
|
(5) 기존 테이블에 현재 수강 주차 테이블 합치기
|
#concat() 함수를 이용하여, sparta_data 테이블과, cuts 테이블 병합 할수 있습니다 :)
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
|
(6) 테이블 컬럼 이름 변경 하기

⇒ 위와 같이, 수강 주차의 컬럼의 이름을 수정 해 줄 필요 있습니다!
|
# 귀찮더라도, 우리가 원하는 컬럼의 이름을 다 작성해 줍시다!
sparta_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
sparta_data.head()
|

(4) 데이터 분석하기
step 1) 수강 시작 주와, 수강 주차를 기준으로 테이블 만들기
⇒ “기준”으로 테이블을 묶으려면.. 어떤 함수가 필요 하다고 했죠?
맞습니다..! groupby 😃
수강 시작 주, 주차 기준으로 테이블 만들기
|
#기존의 테이블을, start_week와, week로 묶어줍니다!
grouping = sparta_data.groupby(['start_week','week'])
grouping.head()
|

step 2) 수강 시작 주와, 수강 주차에 각 해당하는 수강생 수 구하고, 테이블로 변경하기
수강 수 구하기 그리고 테이블로 변경 하기
|
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(5)
|

step 3) 수강 주차 별, 수강한 총 인원 구하기
⇒ 각 주차별에 머물러 있는 수강생 수는 구했지만,
우리에게 필요한 것은 수강 주차별 수강을 완료한 총 인원 입니다!
수강 주차 별 수강한 총 인원 구하기
|
#첫 주가 31주니 변수를 하나 만들어 줍니다!
f=31
#처음 수강 시작한 주의 범위가 {31,32,33,34,35,36} 이니, range(6)으로 합시다!
for i in range(6):
#5주차의 강의가 마지막이고, 0주차까지 이니, 시작은 5에서 시작해 1씩 0까지 감소 시킬수 있어요!
for j in range(5, 0, -1):
cohort_data.at[(f,j-1), 'user_id'] = int(cohort_data.at[(f,j),'user_id']) + int(cohort_data.at[(f,j-1),'user_id'])
#주차는(31부터 32 33..) 1씩 늘어나죠?
f=f+1
|
- 여기서 잠깐 at 함수가 무엇인가요?
- at() 함수를 이용하여 테이블의 하나의 요소에 접근 할수 있습니다 .
- step4) cohort_data에 인덱스 설정하기
- [코드스니펫] - 인덱스 새롭게 설정 하기
|
cohort_data = cohort_data.reset_index()
cohort_data.head()
|

[데이터분석] 프로덕트 개선은 정말 도움이 되었을까_ 시각화
1) 데이터 시각화
|
step 1) 피벗 테이블 만들기
(1) 피벗 테이블이란?
기존의 데이터를 바탕으로 필드를 재구성해,
데이터 통계를 보다 쉽게 파악 할수 있도록 만든 테이블 입니다.
(2) 왜 피벗 테이블을 만들어야 하나요?
데이터 분석 결과를 한눈에 볼수 있어요!
우리가 만든 테이블로는 수강 시작 주당 수강 주차별 인원을 한눈에 파악하기 힘듭니다.
하지만 피벗테이블로, 우리가 원하는 열과 행으로 데이터를 다시 한번 재구성하면
한 눈에 데이터 내용을 파악할 수 있겠죠-?
|

피벗테이블 만들기
|
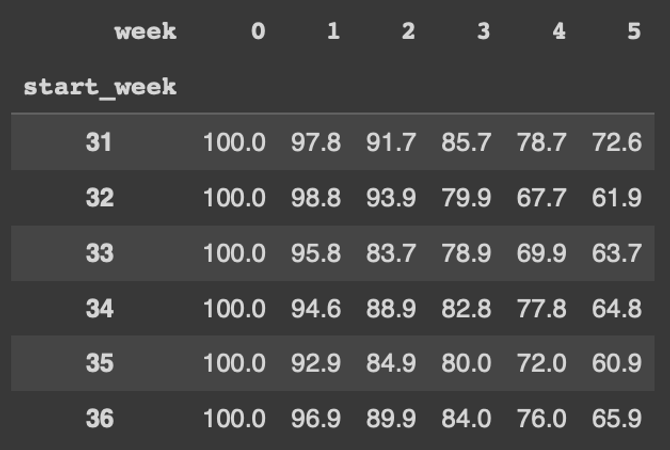
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
|

step 2) 좀 더 가시화 시키기! 표의 데이터를 퍼센테이지로 나타내 봅시다!
|
수강 총 인원을 퍼센테이지로 변경한 테이블이 필요한 이유
우리가 고객의 “수”로 고객 수강 이탈을 판단하는건 쉽지 않아요!
개강일별로 전체 인원이 모두 다르기 때문입니다!
그래서, 고객의 행동이 얼만큼 변화가 있는지에 대한 부분을 비율로 나타내면
좀 더 한 눈에 알아 볼수 있는 분석 결과가 됩니다!
=> 이것을 리텐션 테이블이라고 합니다
리텐션이란?
고객이 우리 제품이나 서비스를 지속적으로 소비하는 것을 의미 합니다!
그러니 이것을 수치화해 기간을 나눠 테이블로 나타내면 지속적으로 고객이 우리의 서비스를 사용하는지 여부를 쉽게 알 수 있겠죠?😀
|
|
(1) 리텐션 테이블 생성 및 각 데이터에 나눠 줄 수강 시작 주 총 인원 구하기
⇒ 퍼센테이지를 구할 때, 필요한 “수강 첫 주” 총 인원을 구해 봅시다!
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts
#각 주(week) 별 최초 수강생 수만 가져오기 (나눠줄때, 분모가 되는 부분!)
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
|
여기서 0 은 첫 번째 열만 들고 가겠다, :은 모든 행을 의미

|
(2) 각 데이터에 수강 시작 주의 총 인원 나눠주기
각 주당 수강생 수강율 나타내기
# 표의 단일 데이터에 최초 수강생의 수를 나누어, 각 주당 수강생 수강율 나타내기!
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.head()
|
|
(3) 각 데이어 퍼센테이지로 변경하기
⇒ 더 알아보기 쉽게, %로 변경 해봅시다!
#각 수치 퍼센트로 변경하기
#round 함수로 3자리 수에서 반올림 한 후, 100을 곱해 줍니다!
retention.round(3)*100
|
* round(3): 이거를 세자리 수 까지 끊겠다.
|
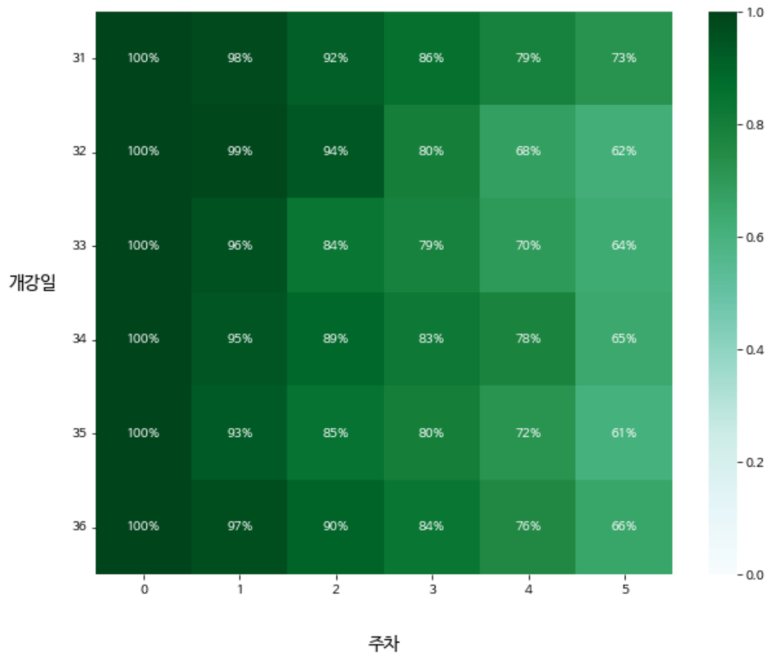
step 3) 코호트 분석 히트맵으로 시각화 하기
왜 히트맵을 사용 할까요? 🤔
⇒ 히트맵을 사용하면, 두 개의 카테고리 값에 대한 값 변화를 한눈에 알아보기 쉽기 때문 입니다😊
⇒ 주의 ❗ 히트맵을 사용하려면, 우선 seaborn 라이브러리를 불러 오는 것이 필요 해요
#테이블 크기 설정 하기
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
#y축 레이블 축 변경 하기
plt.yticks(rotation=360)
#테이블 보여주기
plt.show()
|
|
잠깐, “전환율”이기 때문에 3주차를 문제 없이 들은 사람만 4주차로 갔겠죠?
그래서 저희는 4주차를 확인해야합니다.
|
|
결과 추론 하기
“지난 8월 둘째 주부터 시행한 3주차 커리큘럼 변경 건이 수강 완주율에 어떤 영향을 주었는가” 에 대한
데이터 분석을 진행해보았는데요!
바꾸었던 3주차 전환을 나타내는 4주 차 컬럼에서만 떨어진 것이 아니라 전체적으로 떨어진 것을 볼 수 있습니다! 추가적으로 4주 차 칼럼이 일정하게 떨어져서 유지되고 있지도 않네요!
다른 요인 때문에 완주율이 떨어졌다고 보는 것이 맞을 것 같습니다
|
|
[최종코드]
#라이브러리 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
# 한글깨짐 방지
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_table('파일경로',sep=',')
sparta_data.tail()
#날짜 데이터 타입 변경
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['start_time'] = pd.to_datetime(sparta_data['created_at'], format=format,infer_datetime_format=True)
sparta_data.tail()
#시작 week 구하기
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
sparta_data.tail()
#시작 주 범위 알기
category_range = set(sparta_data['start_week'])
category_range
# 범주화 하기
#번주화할 데이터
progress_rate = list(sparta_data['progress_rate'])
progress_rate
#범주를 구분하는 기준 bins
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
#구분한 범주의 라벨 labels
labes=[0,1,2,3,4,5]
#범주화에 사용하는 함수 pd.cut
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labes)
cuts
cuts = pd.DataFrame(cuts)
cuts.tail()
# 표 합치기
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
#표 인덱스 변경하기
sparta_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
sparta_data.head()
#시작주와, 수강 주차별 기준으로 표 grouping 하기
grouping = sparta_data.groupby(['start_week','week'])
grouping.head()
#시작주와, 수강 주차별에 해당하는 수강생 수 구하기
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(10)
#각 주차별 수강한 수강생 총 합 구하기
k=31
for i in range(6):
for j in range(5, 0, -1):
cohort_data.at[(k,j-1), 'user_id'] = int(cohort_data.at[(k,j),'user_id']) + int(cohort_data.at[(k,j-1),'user_id'])
k=k+1
cohort_data = cohort_data.reset_index()
cohort_data.head()
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts
#각 주(week) 별 최초 수강생 수만 가져오기
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
# 최초 수강생 수를 각 데이터에 나눠주기
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention
#각 수치 퍼센트로 변경하기
retention.round(3)*100
#테이블 크기 설정 하기
plt.figure(figsize=(10,8))
sns.heatmap(data="필요한 데이터 입력하기",
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()
|
'개발일지 > TIL' 카테고리의 다른 글
| [TIL/ Today I Learned] 20240103, 역순 동물 정렬, 중복제거하기 (0) | 2024.01.05 |
|---|---|
| [TIL / Today I Learned] 20231229_ Group by절 사용 질문 (1) | 2023.12.29 |
| [TIL / Today I Learned] 20231227_groupby 질문 (0) | 2023.12.27 |
| [TIL/ Today I Learned] 20231226 (1) | 2023.12.27 |
| [TIL/Today I Learned] 수강생들이 가장 많이 혹은 가장 적게 듣는 시간과 요일을 데이터 분석으로 찾기 (1) | 2023.12.22 |



